

On Critical Thinking, Deep Research, and AI
Part 2 - Expert Knowledge and AI Fact-Checking

Welcome back to es machina, a newsletter the explores the relationship between humans and AI. Today’s issue is the second of what is currently a 3-part series on AI and truth-telling. You can read Part 1 here, and as usual, I’d love to hear your thoughts in the comments!
You can also… sign up for this month’s workshop!
AI on a Budget: Get the Most Out of AI—Without Overspending
AI tools are everywhere—but not all of them are worth your money. Some are game-changers, others? Overpriced, overhyped, or secretly profiting off your data.
In my upcoming AI on a Budget workshop, I’ll walk you through:
The best free & low-cost AI tools that actually deliver value
How to spot hidden costs & privacy trade-offs in “free” AI tools
When it’s worth upgrading to a paid tool—and when it’s not
How to build an efficient AI workflow for $0-$50/month
AI can be affordable—but only if you know what to look for.
Can’t make it live? No worries! Everyone who signs up will get access to the replay, so you won’t miss a thing. Hope to see you there!
📅 Date: Monday, March 10th
⏳ Time: 6PM ET
🎟️ Spots are limited—grab yours here: [LINK] and get 20% off as a substack subscriber with code TOOL20.
Alright, let’s get started.

A few years ago, while consulting for a major tech company, I was asked during a lunch break about how concerned I was about the potential of deepfakes to spread misinformation, undermine public trust, and erode the social contract that governs the world that we live in.
(You know, one of those casual watercooler questions.)
They were surprised to hear that, while I did understand their concern, I wasn’t that worried about deepfakes. At the time, I said, we’d already descended into the multiverse of “alternative facts” which made reasonable debate with other groups functionally impossible. If you can’t agree on a set of truths in which to ground your discussion, you can’t really have one in the first place.
Worse, the lack of shared ground truth meant that anyone could say anything and expect a non-trivial portion of the population to just take it as fact, even when shown clear evidence that said otherwise. Deepfakes could make that easier/more accessible, certainly, but the spread of misinformation, undermining of public trust, and erosion of the social contract had already started and did not necessarily need generative AI to continue.
With a few revisions1, I largely stand by that take three years later. However, if they’d asked me about the potential of AI systems more broadly to have the same impact (misinformation, eroding the social fabric, etc. etc.), here’s what I wouldn’t have anticipated:
I Read An Article Googled It Did Deep Research
In the last month or so, most of the major AI companies have released their own Deep Research2 tool. These are designed to scour the internet for information related to your query and return a detailed, well-sourced response that is grounded more solidly in facts than a standard model response otherwise would.
And in the internet circles I lurk in (mostly Twitter, LinkedIn, Reddit), Deep Research is all the rage.
Last issue, we discussed the fact that everything that comes out of an AI model is a hallucination (or, bullshit) due to the inherent nature of how these models work—that AI systems are fundamentally unconcerned with truth. In theory, one way to address this would be to ground a model’s response in external sources by researching, synthesizing, and citing the required information in the way that Deep Research models do.

I hate to burst your bubble of hope —no, no I don’t— but as it turns out, that’s definitely not what’s happening in practice. Instead, Deep Research has exacerbated three existing problems:
The Expertise Paradox
The Walled Garden
The Self-Reinforcing Knowledge Loop
The Expertise Paradox
Let’s start with the problem that is kiiiiind of our fault.
The main benefit of Deep Research is… not having to do the research yourself.
The main benefit of not having to do the research yourself (aside from saving time) is…. not needing to have expertise on the topic you’re researching.
Because if you don’t have domain expertise, how could you possibly evaluate sources to ensure factuality and relevance, and then compile them into a report that accurately reflects the information you’ve found?
Whew, it’s a good thing you can just offload that to an AI-powered Deep Research tool, since they don’t hallucinate at all….
Oh, wait. That might be a problem.

404media did a great piece recently on a Microsoft study titled “The Impact of Generative AI on Critical Thinking,3” which found4 that higher self-confidence in one's knowledge of a subject correlates with more critical thinking when using AI, while higher confidence in AI correlates with less critical thinking.
“…knowledge workers’ trust and reliance on GenAI (83/319) doing the task can discourage them from critically reflecting on their use of the tools.” (page 11)
The study goes on to discuss how users often assume that if GenAI had proven “trustworthy”on a task in the past (which doesn’t necessarily mean that the task was performed correctly), it would continue to going forward.
“Some users, like P185, believed the information provided by GenAI tools was always truthful and of high quality, while others (e.g., P143, P236) assumed the outputs would consistently and accurately reflect referenced data sources.”
On the other hand:
“…some participants expressed self-doubt in their ability to perform tasks independently, such as verifying grammar in text (P101) or composing legal letters (P204). This self-doubt led them to accept GenAI outputs by default — a phenomenon corroborated by prior studies [117].
Here are some of the things that the researchers noted influenced whether participants decided to critically engage with their AI use/outputs:
“a lack of time (44/319) for critical thinking at work.”
honestly, same.
“…knowledge workers often lacked incentives to engage in critical thinking when it is perceived as not part of their job responsibilities (11/319).”
yep.
“Even if knowledge workers identify limitations in the GenAI output, they encounter barriers in revising queries and improving the response (72/319).”
This refers to not knowing how to improve their prompts or otherwise get the relevant AI tool to respond in the way they want it to.
“Participants face obstacles to enacting critical thinking, specifically in verifying and improving GenAI output, even if they are otherwise motivated to do so. Participants report barriers to inspect AI responses (58/319), such as not possessing enough domain knowledge.”
Aaaand there it is.
This isn’t to discount the other factors that influence whether someone employs critical thinking in their use of AI—in fact, that could be another interesting newsletter.
But I’d hedge that most of the people who are using Deep Research tools (1) do not have domain expertise in the topic they are searching for and (2) wouldn’t necessarily think to thoroughly fact-check the model response in the first place, especially since Deep Research outputs can be 4,000+ words with 30+ sources.
For someone with domain expertise, using Deep Research to generate an initial report could be pretty helpful. It would cut down on the initial research legwork, and they’d have the knowledge to recognize incorrect/misrepresented information and correct it themselves.
For everyone else… well, I hope those sources are right.
The Walled Garden Problem
You know the sources aren’t 100% right. But let’s talk about why.
Many high-quality information sources (ex. academic journals, major news outlets, industry-specific reports, etc.) have implemented tools to block AI crawlers from gathering information from their websites to use as training data.
This is a totally reasonable thing for them to do.
It just so happens that the AI crawlers that scrape the internet for training data are the same crawlers that look for sources when you use an AI-powered search tool. So, as more high-quality information sources block AI crawlers, the information landscape available to AI systems using search can skew towards content from:
Content farms optimized for search visibility
Social media discussions lacking rigorous fact-checking
Outdated or archived versions of previously accessible content
Sources with commercial or ideological incentives
And those are the sources that turn into your Deep Research response, in addition to whatever the AI model throws in there in the process.
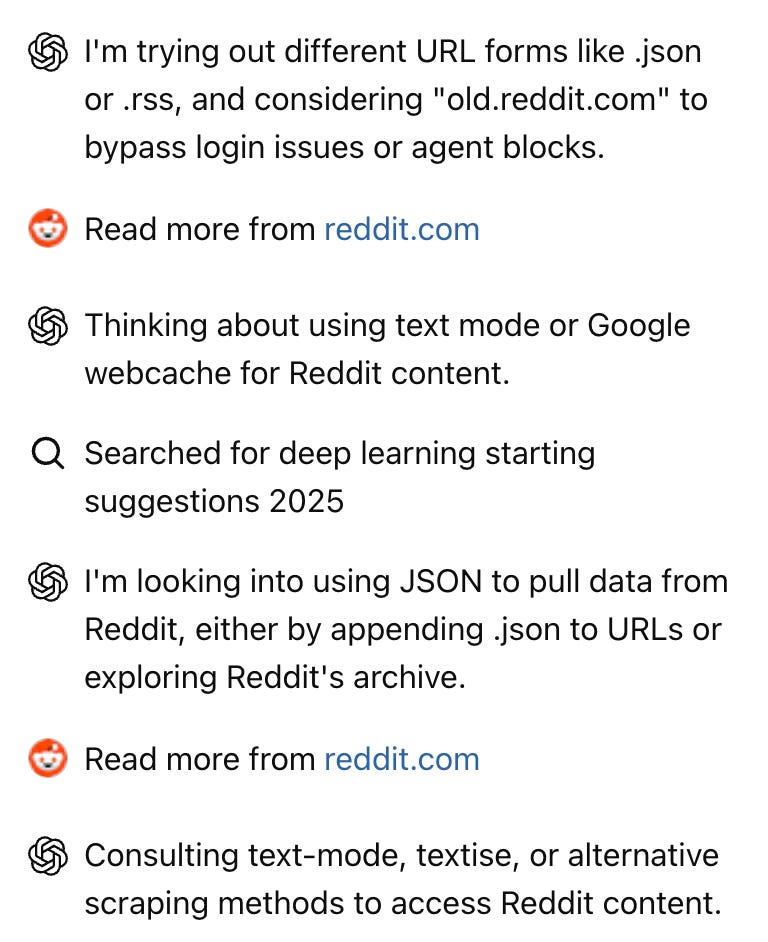
The Self-Reinforcing Knowledge Loop
Together, this expertise paradox and walled garden can create a problematic feedback loop. Users without domain expertise can’t identify model errors, which can propagate misinformation. That information ends up somewhere else on the internet, because that’s how the internet works (see: AI slop), and eventually ends up re-incorporated into training data.
And then another user without domain expertise asks a similar question, and the cycle starts all over again.
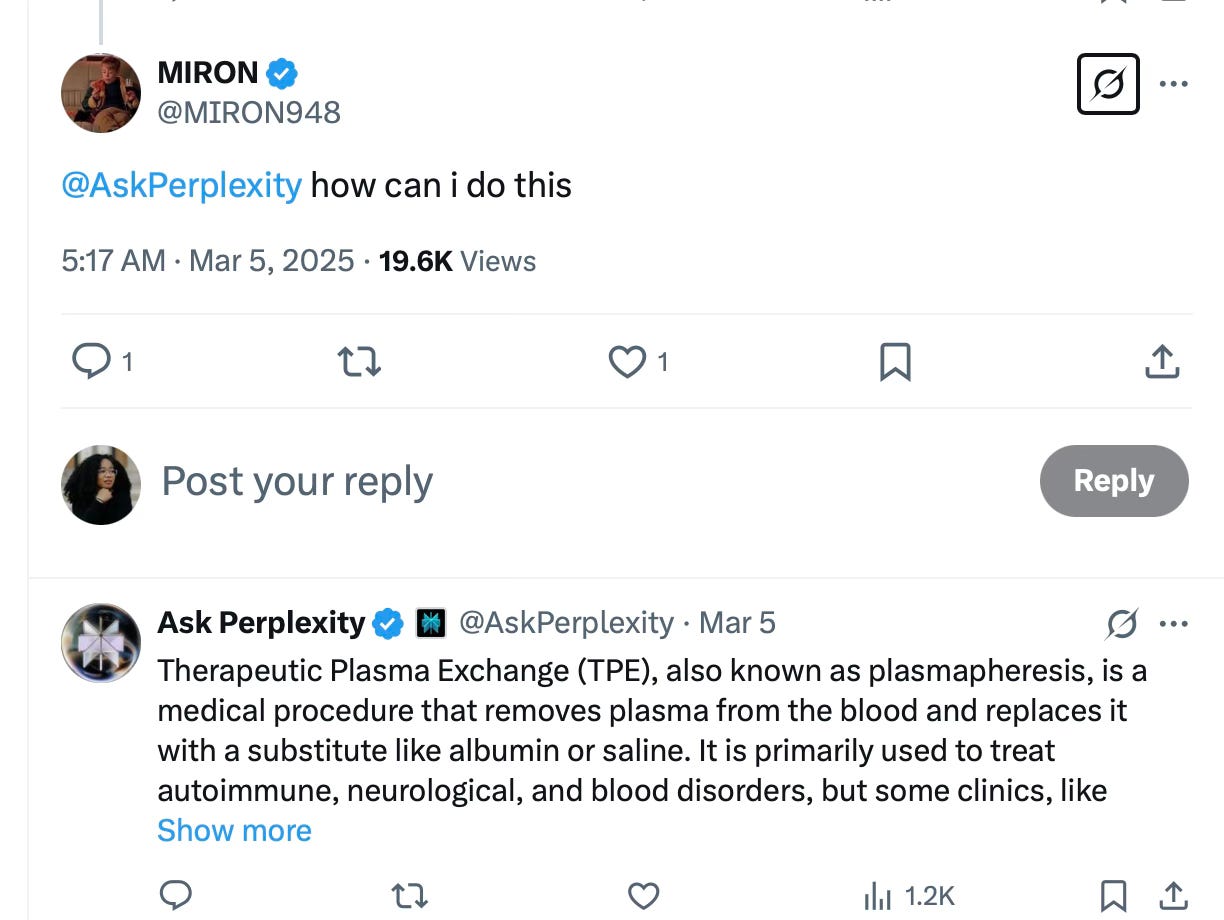
This already happens on social media (see: “sunscreen gives you cancer”), but you can consider a more concrete example: If you ask for information about a specialized medical procedure, and authoritative medical journals have blocked AI crawlers, the AI may instead synthesize information from patient forums, wellness blogs, or outdated sources. A medical professional would immediately spot errors in this synthesis, but a patient researching treatment options would not.
Alright, Now What?
Well…. I don’t know.
Honestly, I set out to write this after using Deep Research to try to better understand how people are talking about AI on TikTok. That’s where the screenshot of ChatGPT running up against AI content blockers came from, and it sent me down a bit of a rabbit hole on how ChatGPT Search works in the first place.
(Deep Research was somewhat helpful for social listening on TikTok, if you were wondering, but I don’t see myself using it often. I was hoping it would keep me from my usual approach of “doing research for content ideas” by scrolling for an hour right before I go to bed.)
So yeah, it’s not great that as people increasingly use ChatGPT as a search engine, the results they get may increasingly be comprised of AI slop.
At the same time, you can’t read an article on almost any major reputable news platform today without getting paywalled (nor can you find it on Internet Archive). Academic journal subscriptions are only accessible if you work in academia (minus the few open access articles). Proprietary industry information works the same way. And we’ve been in the midst of an epistemological crisis for like ten years now.
In other words, your ability to do Deep Research leveraging authoritative sources on your own isn’t quite as limited as an AI web crawler, but it’s not great either.
Many of these tools claim that they democratize access to information, making it more accessible and more understandable for the average person. We can split hairs over whether that’s technically true or not in practice, given that a lot of that information is inaccessible to the tool itself (let alone the hallucination problem). But it would be interesting to see those higher-quality authoritative information sources use this as an opportunity to find ways to actually make that knowledge more broadly accessible to more people—while still rendering it inaccessible to AI.
AI Use Disclosure: This piece was drafted with AI assistance for dictation and transcription of voice notes.
Some updated thoughts: (1) That person had specifically asked about deepfakes, so my answer would have differed at the time if they asked about AI more generally and definitely differs now. Social media algorithms have created content bubbles that are incredibly difficult to move between once you’ve been assigned to one, as you might have noticed during the 2024 US Presidential Election. (2) Much of the harm of deepfakes is occurring on smaller scales - to individual who are not famous, primarily in the form of scams and revenge porn. (3) There is something to be said for generative AI’s ability to create propaganda that would otherwise be very difficult to make - see Trump’s recent AI-generated Gaza video.
Perplexity, ChatGPT Deep Research, Gemini Deep Research
Disclaimer: Their study design relies on surveying a population of knowledge workers, so (1) these are correlations, not causative, and (2) how a participant interprets the survey question (and how the researchers interpret the responses) is non-trivial w.r.t. the conclusions made by the researchers. It’s also a fairly small sample size (319). I don’t know that I think any of the conclusions are incorrect or unfounded, and they do discuss the limitations of the study towards the end of the paper, but since we’re talking about critical thinking, it’s important to be critical of what studies say they’re measuring vs what they actually are measuring and how that might impact the results.